No more 'us and them': Part 4 - Building tools to enable story-telling
How 20 years of digital communications smashed the boundaries between media and audience
So far in this series of blog posts I've looked at forms of communication between media companies and their audiences, either en masse or in newer, more personal ways. But publishers are also becoming digital communication platforms. For an organisation like the Guardian, this has meant moving from being a place where journalists tell stories, to a place where we enable stories to be told.
The new Government in the UK has begun a process of releasing vast amounts of public data. Often this takes the form of large spreadsheets, that are unwieldy to process. With both the release of the COINS database, and the more recent set of spending figures, the Guardian Datablog and tech team have worked together to put an easier user interface onto the data. It means that users of the website can start to explore the data without having to learn the intricacies of how it was put together.
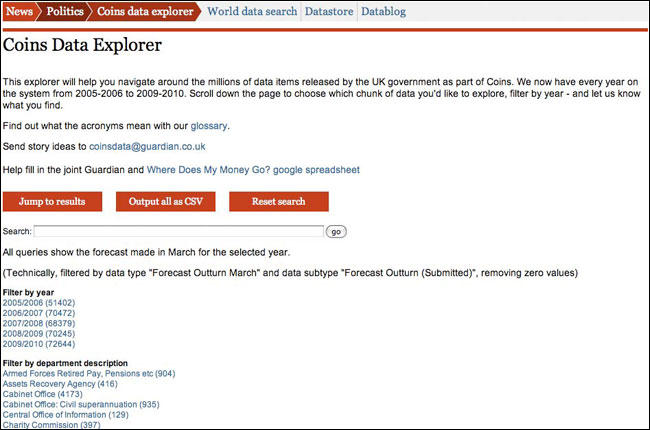
The 'Coins Data Explorer' on guardian.co.uk
In a similar way, the guardian.co.uk site features a World Government Data search engine. We have been aggregating the civic and state datasets being released in countries like the UK, US, Canada and New Zealand, and presenting them as one set. Local level datasets like those published by New South Wales, Vancouver and Lichfield are also included. This gives developers a one-stop shop to compare similar datasets across country boundaries.
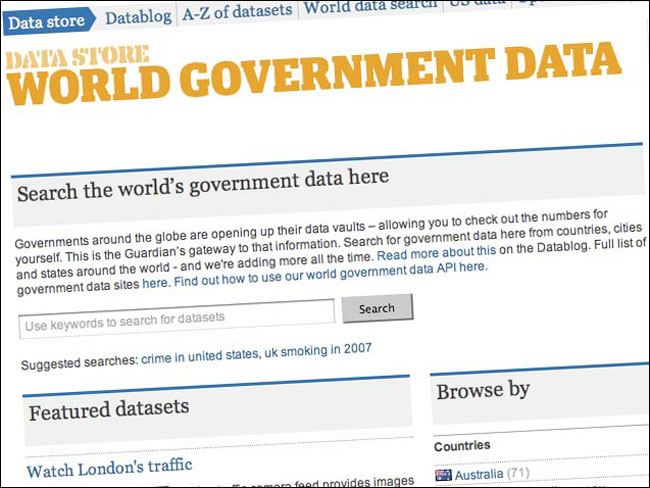
The World Government Data store on guardian.co.uk
Improving machine-to-machine communication
Another emerging digital communication theme of the early 21st century is the drive towards the semantic web, and interoperable machine-to-machine communication about data across the internet. At the moment the web is a web of documents, but as Tom Scott at the BBC observes in his presentations about their work in the semantic web area, people don't care about documents, they care about things.
The strictly academic ontology-heavy approach to implementing the semantic web has met with some resistance - in fact earlier this year Tom Coates issued the war cry "Death to the semantic web". An alternative to the top-down approach which insists on SPARQL, OWL, RDFa and one ontology to rule them all, is the world of open linked data. This offers a structure of databases scattered around the network which know a little about how to be interoperable with at least one other, and share some common identifiers. The 'linked open data cloud diagram' illustrates this 'small pieces loosely joined' approach very well.
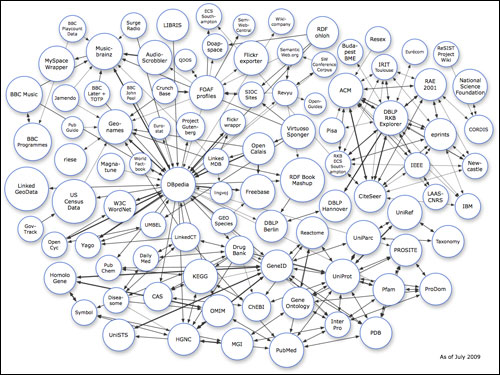
The linked data universe diagram
At Guardian News & Media we have taken our first tentative steps into the arena of linked data. It is now possible to query the Guardian's content API using MusicBrianz IDs or ISBN numbers. Using these external common identifiers you can pull back reviews of a specific book or articles about a specific music artist with greater precision than a purely text search can. As I blogged on guardian.co.uk about it:
"An ISBN query of http://explorer.content.guardianapis.com/#/search?reference=isbn/9781847371355&show-references=all will return our review of Peter Hook's book The Haçienda: How Not to Run a Club.
MusicBrainz, meanwhile, is a wiki-based site that aims to have a page and a unique ID for every recording artist or composer that ever existed, so 2cd475bb-1abd-40c4-9904-6d4b691c752c represents Franz Liszt and 2aaf7396-6ab8-40f3-9776-a41c42c8e26 represents LCD Soundsystem. To search for our content about New Order, you can insert their MusicBrainz ID into a query - http://explorer.content.guardianapis.com/#/search?reference=musicbrainz/f1106b17-dcbb-45f6-b938-199ccfab50cc&show-references=all
Already this throws up some intriguing possibilities. Searching for f1106b17-dcbb-45f6-b938-199ccfab50cc also returns our review of Peter Hook's Haçienda book, as he was the bassist in the band, and New Order were part-owners of the club in question. We can now use the Open Platform API to infer that ISBN 9781847371355 is related in some way to MusicBrainz ID f1106b17-dcbb-45f6-b938-199ccfab50cc, using Luke Bainbridge's Observer review of the book as the linking element."
Next...
In the final part of this series, I'll look at how the new open way that media companies have to deal with their audience extends to the way that products are developed, and show how Guardian News & Media gives the audience background information on product development, and gets them to participate in product design through user testing.
MusicBrainz is NOT a wiki-based site.
It's a database, with a frontend site and a webservice.
In the second paragraph of the MusicBrainz about page, it says "the project has expanded its scope from being a CDDB replacement to a true 'Wikipedia for music'"