Looking at Lycos Retriever Beta
Due to the overwhelming market share that it enjoys, frequently even the rumour that Google is going to introduce a new feature or product can make global news headlines. Meanwhile a lot of the search engines with smaller market share are producing some interesting new takes on search and web navigation, with barely a fanfare. One such product is Lycos Retriever - which they claim is "the Web's first information fusion engine".
The product is an attempt to build a directory where each page contains not just links about a specific topic, but also displays in-depth information about that topic.
Retriever Topic pages include meaty extracts from high-quality Web pages which give you basic information and let you know where to go for more. Each Topic page focuses not on a word, but an idea. It also gives you helpful links to pages that tell you more about specific aspects of the basic idea.
Retriever evaluates both the quality and the freshness of the information it's reporting. What it returns to the user is a briefing book, with perspectives from all over the Web, not a dry encyclopedia article or one person's opinion on a subject.
Lycos go on to claim that the system is fully automated, and builds the directory based on the most popular queries. Once given a query to examine, the system uses natural language processing to select the best pages about the topic from the web, and then selects the most relevant paragraphs from those pages to build the extracts it displays.
The site isn't fully Web 2.0 buzzword compliant despite having a 'beta' label and a claim of wisdom-of-crowds-meets-AI about it. There is no tagging or way for users to reclassify or save the information for a start, although the pages do include two ways to submit feedback. Each excerpt can be voted 'helpful' or 'not helpful'. Lycos explain that:
Of course, like any automatic process, it's not perfect. Sometimes the paragraphs we choose will be off-topic or inappropriate, which is why we give you the ability to tell us how you like them.
The voting mechanism is anonymous, and done with JavaScript so it does not force a reload of the whole page. There is also a box to submit suggestions for other topics that Lycos Retriever should cover.
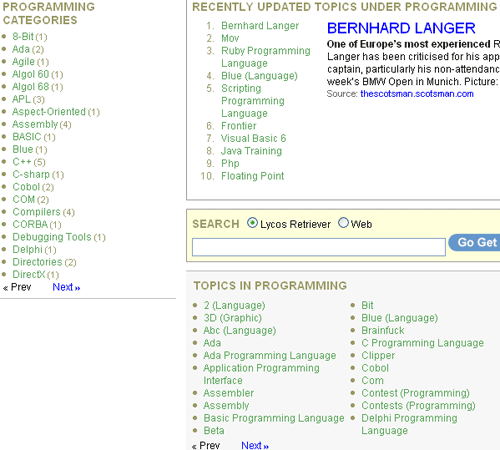
I found the topics covered to be quite shallow at the moment, and was surprised for example that there is a sub-topic "Tour de France" under "Kraftwerk", but no coverage of the epic "Tour de France" cycle race itself. Equally I was surprised that a subsequent search on Retriever for "Tour de France" didn't uncover the "Kraftwerk: Tour de France" page I'd already seen.


I was also a little confused as to the way their automatic taxonomy is being built and the consequent distinction between a category and a topic. For example why are Blue, Cobol, Com and Delphi all listed as both categories and topics under 'programming'? And, come to that, why is Ryder Cup golf captain Bernhard Langer the most recently updated topic under programming at all?
Despite the failings so far, it looks like an interesting move into the market for finding a way to use machines to scale-up the ability to build an accurate and dynamic directory of the web, in a way that DMOZ and Yahoo! never managed. However, not everybody is happy with the concept, and tomorrow I will be looking at some of the objections being made to the way Lycos is running the Lycos Retriever product.